-
Most important feature of instruction set design -
-
make opcodes easy to decode.
-
-
The easiest way to do this -
-
break up the opcode into several different bit fields.
-
-
Opcode fields:

CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm
Since opcodes are submitted to the decoder circuits, encoding opcodes is quite more involved rather than just assigning numbers.
|
|
Each field is contributing part of the information necessary to execute the full instruction.
The smaller the bit fields, the easier it is for hardware to decode them.
Suppose we decided to design a brand-new CPU with a set of 7-bit opcodes.
With an opcode of this size we could encode 27 = 128 different instructions.
Decoding individual instructions requires a 7-line to 128-line decoder - an expensive piece of circuitry.
If you have 128 truly unique instructions, there's little you can do other than to decode each instruction individually.
However, assuming our instructions contain certain patterns, we could reduce the hardware cost by replacing this large decoder with a few smaller decoders.
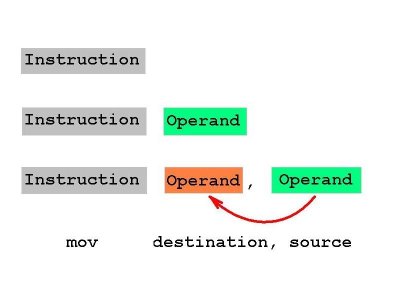
For example, on the x86 CPUs the opcodes for
mov eax, ebx ; copy data from EBX register to EAX register
and
mov ecx, edx ; copy data from EDX register to ECX register
are different, but both instructions are related: they both move data from one register to another.
The only difference between the two MOVs is the source and destination operands.
This suggests that we could encode instructions like MOV with a sub-opcode and encode the operands using other bits within the opcode.
Another important criteria: keep instruction sizes within a reasonable range.
CPU with unnecessarily long instructions will consume extra memory for programs in memory.
Long instructions hurt overall CPU performance.
Using encoding with n-bit size opcodes leaves us with 2n different instructions.
With n bits, it seems like you can't do it with any fewer but 2n opcodes.
We can make some opcodes longer than n bits...
...and that is the secret to reducing the size of a typical program on the CPU!
(This strategy is acceptable only for CISC processors; RISC(*) processors prefer uniform 32-bit or 64-bit instructions.)
Assuming that CPU is capable of reading byte-sized quantities from memory, each opcode must be some even multiple of 8-bits long.
Another point to consider is the space for instruction operands:
RISC designers include all operands in their opcode.
CISC designers, including x86, place constants and address displacements (offsets) apart from the opcode.
______________
(*) CISC stands for
design,
while RISC is a
Most of processors predating the 8086 had 8-bit opcodes, allowing 256 different instructions.
A two-byte opcode would allow 65,536 different instructions...
...but from a practical standpoint,
most-frequently-used instructions continue to have 8-bit opcodes,
less-frequently-used instructions have two-byte opcodes,
three (or more) byte opcodes are mostly for the rarely-used-instructions.
Such strategy makes a typical program significantly shorter, compared to a uniform two-byte opcode.
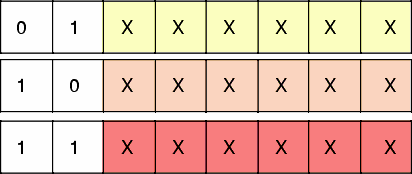
Assume that two high-order bits of an imaginary opcode are not 00, and the opcode size is strictly one byte long.
The 6-bit field marked xxxxxx provides 26 = 64 unique bit patterns.
Together with three non-zero high-order combinations (01, 10, and 11), 192 different one-byte instructions can be encoded:
64 × 3 = 192
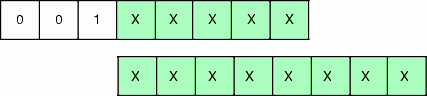
Assume that if three high-order bits of the opcode are equal 001, it signals that the opcode size is two bytes.
If so, the remaining 13 bits of the total 16-bit opcode let us encode
213 = 8192
different instructions.
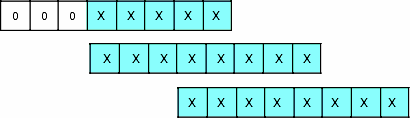
If three high-order bits of the opcode are equal 000, the imaginary opcode is three bytes long.
If so, the remaining 21 bits of the total 24-bit opcode let us encode two million (221) different instructions.
Although we are able modify opcode sizes to have smaller programs, it comes at a price:
decoding the instructions is a bit more complicated.
Before decoding opcode field, the CPU must first decode the instruction size.
This extra step hurts the performance.
These are the reasons, along with some others, why most popular RISC architectures avoid variable-sized instructions.
However, x86 uses the variable-length opcodes, since saving memory is such an admirable goal.
There will be a need for new instructions in the future.
Reserving some opcodes specifically for that purpose is a really good idea.
For example, reserving a block of 64 one-byte opcodes may seem extravagant, but could also be a rewarding foresight!
Keep in mind that it's much easier to add an instruction later than to remove it.
For starters, it's better to stick with simpler design rather than a more complex one.
First step: let's choose some generic instruction types for a brand-new CPU.
For example, most processors will have instructions like the following:
Data movement instructions (e.g., MOV)
Arithmetic and logical instructions (e.g., ADD, SUB, AND, OR, NOT)
Comparison instruction, CMP
A set of conditional jump instructions JE, JNE, etc., generally used after the compare instructions.
Input/Output instructions GET and PUT.
The bottom line: allow programmers to efficiently write programs using as few instructions as possible.
Once the initial instruction set is determined, next step is to assign opcodes for them.
To do so, instructions are separated into groups with common characteristics:
For example, an ADD instruction supports exact same set of operands as the SUB instruction.
NOT instruction requires a single operand, so does the NEG instruction.
etc.
Once all the instructions are grouped by their respected categories, the next step is to encode the actual opcodes.
|
|
Encoding operands is always a problem, because instructions have large number of operand combinations.
For example, an x86 MOV instruction requires a two-byte opcode.
However, Intel noticed that two instructions
mov memory, eax ; store register in a variable
mov eax, memory ; load register from a variable
occur very frequently. These instructions store EAX register into memory and load EAX from memory.
As a result, x86 provided a special one-byte versions of dedicated MOV instructions to reduce program clutter.
Note that Intel did not remove the two-byte version of these instructions, but compiler or assembler would always emit the shorter of the two instructions.
By doing so, Intel has made an important trade-off with the MOV instruction encoding:
giving up extra opcodes in order to provide a shorter version of the MOV sub-family.
Intel used this trick all over the place to make decoding instructions shorter and easier.
This decision dates back to 1978. Today's design could use extra bytes, but the cost of memory was high in 1978!
Advances in computer architecture technology since 1978 made encoding of x86 instructions quite complex and somewhat illogical.
Despite the lack of simplicity, x86 ISA well deserves studying its design and encoding.
To cope with x86 complexity, let's pretend that we deal with a simplified version of the CPU:
there are only four 16-bit registers: AX, BX, CX, and DX
(therefore, register operands can be encoded with just two bits.)
the address bus is 16-bit with a maximum of 65,536 bytes of addressable memory.
there are only 20 instructions:
MOV (with two forms), ADD, SUB, CMP, AND, OR, NOT,
JE, JNE, JB, JBE, JA, JAE, JMP,
BRK, IRET, HALT, GET, and PUT.
The two forms of the simplified MOV instruction could have the following forms:
mov reg, reg/memory/constant ; load register EAX
mov memory, reg ; store register in memory
where
mov is instruction mnemonic
reg is any of AX, BX, CX, or DX,
constant is a numeric constant (using hexadecimal notation),
memory is an operand specifying a memory location.
|
|
|
|
|
|
|
|
The encoding produces one-byte opcode 110 00 001, or 0C1h.
Instruction
mov ax, [1000h] ; load AX register from memory location 1000h
loads the AX register from memory location 1000h.
The encoding for the opcode is 110 00 110, or 0C6h.
Another encoding,
mov ax, [2000h] ; load AX register from memory location 2000h
is exact same 0C6h, because none of the opcode fields store the memory address.
To accommodate 16-bit address or a constant value, we must add two more bytes to the instruction opcode.
|
|
|
|
There are four possible one-operand instruction classes, specified by 2-bit ii[4:3] field:
The first encoding ii[4:3]=00 further expands the instruction set with a set of zero-operand instructions
The second opcode ii[4:3]=01 is also an expansion opcode codifies all of the simplified jump instructions.
The third opcode ii[4:3]=10 is the NOT instruction, a bitwise logical not operation that inverts all the bits in the destination register or memory operand.
The fourth opcode ii[4:3]=11 is currently unassigned:
Any attempt to execute unassigned opcode will halt the processor with an illegal instruction error.
CPU designers often reserve unassigned opcodes to extend the instruction set at a future date. Intel did so when moving from the 80286 processor to the 80386.
|
|
Therefore, the CPU will fetch the next instruction from this new target address.
Effectively, the program jumps from the point of the JMP instruction to the instruction at the target address.
The JMP instruction is called an unconditional jump instruction, it always transfers control to the target address.
|
|
Conditional jump instruction mechanics are:
Test some condition, and then jump, but only if the condition was true.
Fall through to the next instruction if the condition was false.
Conditional jumps test the results of the preceeding CMP instruction. For example,
cmp bx, 0 ; Is BX = 0?
je is_zero ; Jump if so
...
is_zero:
|
|
|
|
The HALT program terminates program execution.
The GET instruction reads a hexadecimal value from the keyboard and returns this value in the AX register.
The PUT instruction prints the value in the AX register.
|
|
The first method is to directly use the undefined opcodes to define new instructions
(this works best when there are undefined bit patterns within an opcode group and new instruction falls into that same group.)
For example, opcode "000 11 mmm" falls into the same group as the NOT instruction.
If you decided to add NEG (negate, take the two's complement) instruction,
using opcode "000 11 mmm" makes a lot of sense.
NEG instruction uses the same syntax and decoding, as the NOT instruction.
|
|
There is insufficient space in the single operand instruction opcodes.
Currently there is only one open opcode: 000 11 mmm.
A common way to handle the opcode shortage (one the Intel designers have employed) is to use a prefix opcode byte:

Prefix opcode expansion scheme uses an opcode prefix byte as follows:
Decode prefix byte in memory.
Read and decode the next byte in memory as the actual opcode.
However, the second opcode byte uses a completely different encoding scheme.
Therefore, prefix lets you specify as many new instructions as you can encode in that byte (or bytes, if you prefer).
Using a prefix byte to extend the instruction set:
For example, the opcode 0FFh is illegal, since it corresponds to a
mov const, dx ; error: attempt to modify immediate operand
instruction. So, we could use 0FFh as a special prefix byte to further expand the instruction set.